这两天的学习过程对线性代数的认知逐渐清晰,我以此贴,把一些关键新内容汇总于此。
当面对矩阵、奇异值时,应该建立如下认知:
✅ 矩阵是空间操作器
✅ 奇异值分解帮你分解矩阵的精髓:旋转 → 拉伸 → 旋转
✅ 奇异值的大小排序,告诉你:矩阵在哪些方向上真正有力量,哪些方向是废
1、正交矩阵#
正交矩阵(Orthogonal Matrix)的核心定义
一个 n×n 实矩阵 Q 如果满足
QTQ=QQT=In
则称 Q 为正交矩阵。
这里 QT 是转置,In 是 n 阶单位矩阵。
逆即转置
Q−1=QT
计算上省事,数值稳定。
正交矩阵就是 “保持内积” 的实矩阵—— 它把坐标系旋转或翻转,但绝不拉伸或扭曲。
2、尖括号#
在这里
⟨qi,qj⟩
就是 “内积 (inner product)” 的符号。最常见的情形 —— 实数向量空间 Rn—— 它等同于我们熟悉的点积(dot product):
⟨qi,qj⟩=qiTqj=k=1∑n(qi)k(qj)k.
3、矩阵交换位置#
1. 消掉左边的 Q
-
贴在 S左边的是 Q
-
用它的逆 Q−1左乘双方:
Q−1A=Q−1QSQT⟹Q−1A=SQT
注意:
2. 消掉右边的 $Q^{\mathsf T}$
Q−1A(QT)−1=SQT(QT)−1⟹S=Q−1A(QT)−1
若 Q 是正交矩阵,Q−1=QT,于是
S=QTAQ.
为什么顺序不能颠倒?
-
一旦乘错侧,符号会 “插” 到别的位置:
AQ−1=Q−1A。
-
在等号两边必须 对称地 进行相同操作,等式才仍然成立。
-
这本质上与函数复合顺序或坐标变换顺序相同:先做哪个变换、后做哪个变换都写在乘积的对应位置,绝不能随意交换。
4、相似对角化矩阵#
相似对角化矩阵(常说 “可对角化矩阵”)指的是:
存在一个可逆矩阵 P,使得
P−1AP=D,
其中 D 是对角矩阵。
此时说 A 能通过相似变换被对角化,或简称 A 可对角化。
对角化的 “机械流程”
-
求特征值:解 det(A−λI)=0。
-
求特征向量:对每个 λ,解 (A−λI)x=0。
-
组装 P:把 n 个互不相关的特征向量按列排成矩阵 P。
-
得到 D:把对应特征值填进对角线:D=diag(λ1,…,λn)。
就有 A=PDP−1。
5、奇异值分解#
A=QSQT⟺S=QTAQ
| 符号 | 含义 |
|---|
| A | 给定的 实对称矩阵(AT=A) |
| Q | 正交矩阵:QTQ=I,列向量两两正交且单位长度 |
| S | 对角矩阵:S=diag(λ1,…,λn) |
写法 A=QSQT 称为 正交相似对角化;几何上就是 “旋转(或镜像)坐标系 → A 只剩独立的伸缩”。
1. 为什么 “实对称矩阵一定能正交对角化”?
光谱定理:
对任何实对称矩阵 A,存在正交矩阵 Q 使得 QTAQ 是对角的,且对角元就是 A 的特征值。
- 实特征值:对称保证特征值全是实数。
- 正交特征向量:若 λi=λj,对应特征向量必正交。
- 重根也能取正交基:同一特征值可能对应多个向量,这时在它们张成的子空间里再做 Gram–Schmidt 即可。
- 文字步骤逐条解析
| 步骤 | 说明 |
|---|
| 1. 求出 A 的全部特征值和特征向量 | 计算 det(A−λI)=0 得到所有 λi;对每个 λi 解 (A−λiI)v=0 求特征向量。 |
| 2. 将特征值按一定顺序在对角线上排列即可得到对角阵 S | 例如按从小到大排成 S=diag(λ1,…,λn)。顺序无关紧要,只要和稍后列向量顺序一致即可。 |
| 3. 不同特征值对应的特征向量彼此正交;对重根特征向量用 Gram-Schmidt 正交化并单位化 | - 若 λi=λj,对应向量天然正交,不用动。 |
| - 如果 λ 有重复(几何重数 >1),先随便取一组线性无关向量,再在该子空间里做 Gram-Schmidt,使之两两正交并各自归一(长度调成 1)。 | |
| 4. 按照特征值在对角线上的顺序将改造后的特征向量横向排列,即可得到正交矩阵 Q | 按对角线特征值顺序把改造后的特征向量作为列排成 Q=[q1 ⋯ qn]。此时 QTQ=I,并有 A=QSQT。 |
- 一个 2×2 具体小例子
设
A=[4114]
① 求特征值
det(A−λI)=(4−λ)2−1=0⟹λ1=5,λ2=3
② 求特征向量
- λ1=5:(A−5I)v=0 ⇒ v1=[11]
- λ2=3:(A−3I)v=0 ⇒ v2=[1−1]
③ 归一化
q1=21[11],q2=21[1−1]
④ 组装并验证
Q=21[111−1],S=[5003],QTAQ=S.
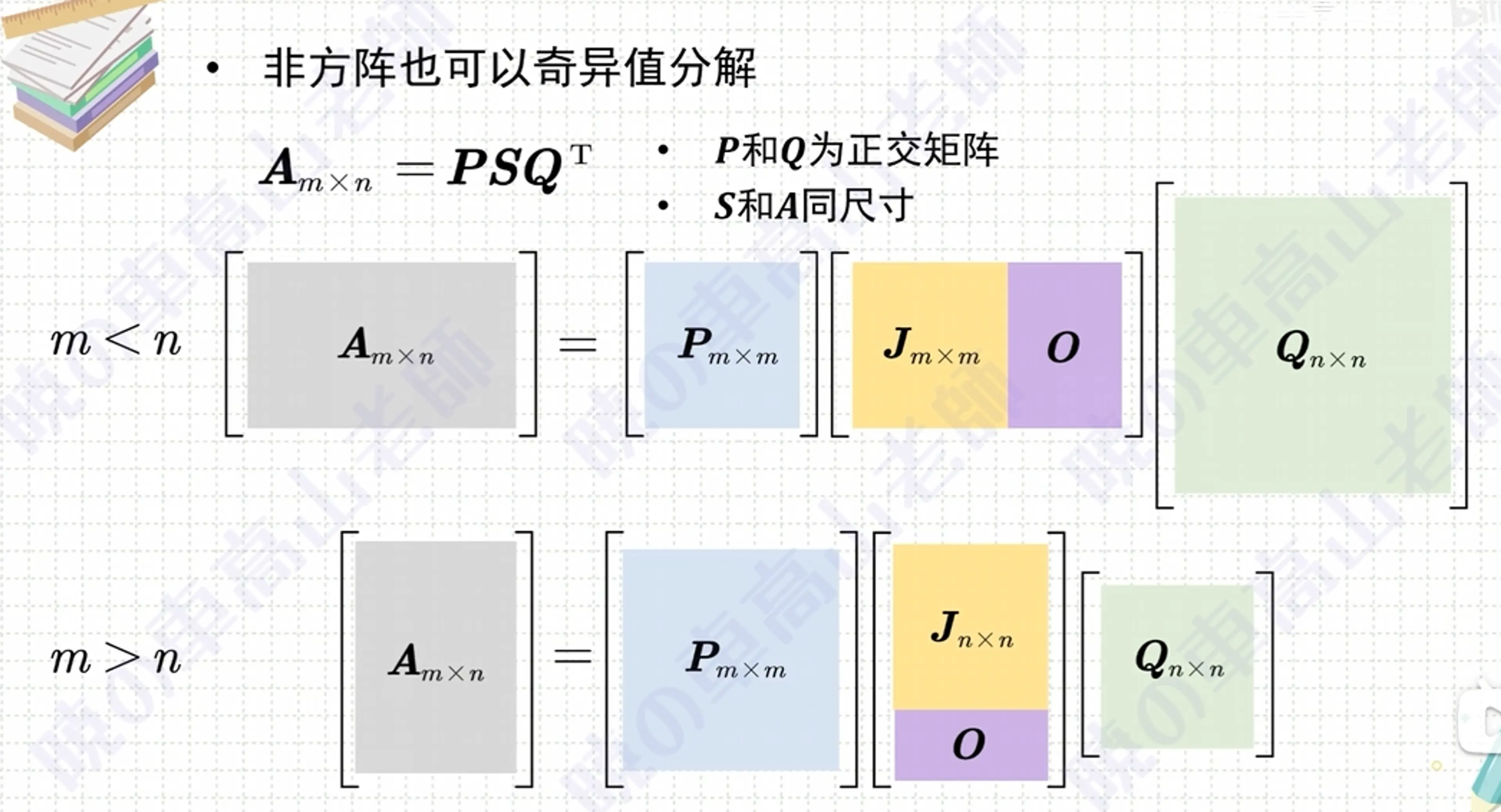



6、取行列式(det・)#
行列式(determinant)是把一个方阵 A 映射成一个标量 detA 的运算。
这个标量综合了矩阵最核心的几何与代数信息:体积伸缩因子、可逆性、特征值乘积等。
公式
| 阶数 | 公式 |
|---|
| 1×1 | det[a]=a |
| 2×2 | det[acbd]=ad−bc |
| 3×3 | “Sarrus 法” 或按第一行展开: |
| detadgbehcfi=a(ei−fh)−b(di−fg)+c(dh−eg) | |
| 核心性质(任何定义都必须满足) | |
| 性质 | 说明 |
|---|
| 乘法性 | det(AB)=detA⋅detB |
| 可逆判据 | detA=0⟺A 可逆 |
| 按行列线性 | 每一行(列)关于元素线性 |
| 交替性 | 两行(列)交换 ⇒ 行列式变号 |
| 对角线积 | 上 / 下三角矩阵:detA=∏iaii |
| 特征值积 | detA=λ1λ2⋯λn(含重数) |
3×3 手算示例
设
A=2051423−10
按第一行展开:
detA=2det[42−10]−1det[05−10]+3det[0542]=2(4⋅0−(−1)⋅2)−1(0⋅0−(−1)⋅5)+3(0⋅2−4⋅5)=2(2)−1(5)+3(−20)=4−5−60=−61.
一句话总结
“取行列式” 就是:让一个 n×n 方阵通过一套交替、线性的规则坍缩成单一数字,这个数字同时编码了矩阵的体积伸缩、方向、可逆性和特征值乘积等关键信息。
7、矩阵的秩#
矩阵的 “秩” 到底是什么?
| 等价视角 | 直观解释 |
|---|
| 线性独立 | 行(或列)里能挑出多少个彼此线性无关的向量,就是秩。 |
| 空间维数 | 列向量张成的子空间(列空间)维度 = 行向量张成的子空间(行空间)维度 = 秩。 |
| 满秩子式 | 矩阵里最大的非零行列式的阶数 = 秩。 |
| 奇异值 | 在 SVD A=UΣV∗ 里,非零奇异值的个数 = 秩。 |
线性独立
下面用 3 × 3 的小矩阵举三个对比案例,让「秩 = 能挑出几根线性无关的列(或行)向量」这句话一目了然。
| 矩阵 $A$ | 列向量写成 (v1∣v2∣v3) | 线性关系 | 秩 |
|------------|-----------------------------------------------|-----------|--------|
| 123246369 | v1=123
v2=246=2v1
v3=369=3v1 | 三列全在同一直线上 ——只有 1 根独立向量 | 1 |
| 101011112 | v1=101
v2=011
v3=v1+v2 | v1,v2 不共线 ⇒ 2 维平面;v3 落在这平面里 | 2 |
| 101011110 | v1=101
v2=011
v3=110 | 任意两列都无法线性表达第三列 ⇒ 三列张成整个 R3 | 3 |
如何判断「无关」?
-
手算 把列拼成矩阵,对它做消元 → 非零行数就是秩。
-
概念 如果存在常数 $c_1,c_2,c_3$ 使 $c_1v_1+c_2v_2+c_3v_3=0$ 且不全为 0,向量就相关;否则无关。
一句话:秩 = 这张矩阵真正 “存得下” 多少独立信息(维度)。
8、低秩近似#
为什么截断 SVD (低秩近似) 只要存 k (m+n)+k 个数?
把原矩阵
A∈Rm×n
截断到秩 $k$ 后写成
Ak=UkΣkVkT,
| 块 | 形状 | 需要保存的标量个数 | 说明 |
|---|
| Uk | m×k | m×k | 左奇异向量:只取前 k 列 |
| Vk | n×k | n×k | 右奇异向量:同理 |
| Σk | k×k对角 | k | 只保留对角线上 k 个奇异值 |
把三块加起来就是
Ukmk+Vknk+Σkk=k(m+n)+k.
因此,用秩 -k 的 SVD 近似替代原来的 m×n 储存量,参数量从 mn 缩到 k(m+n)+k。
如果 k≪min(m,n),省下的空间就非常可观。
秩降低 = 信息维度降低,低秩存储 = 参数量 / 内存同步降低
9、范数#
“两竖线” $|,\cdot,|$ 在线性代数里表示 范数(norm)。
-
对向量 v∈Rm,最常用的是 二范数(Euclidean norm):∥v∥=vTv=∑i=1mvi2,∥v∥2=vTv.
在图中 ∥Xw−y∥2 就是把向量 Xw−y 的每个分量平方后求和。
-
对矩阵 A 若也写 ∥A∥,常默认为 Frobenius 范数:∥A∥F=∑i,jAij2。不过在这张图里涉及的都是向量。
与之对比,单竖线 ∣⋅∣ 通常表示绝对值(标量)或行列式 ∣A∣。所以双竖线是向量/矩阵 “长度” 的符号,单竖线是标量大小或行列式的符号 —— 对象和含义都不同。
向量常用欧几里得距离 -- 2 范数(L2 范数)#
import torch
b = torch.tensor([3.0, 4.0])
print(b.norm()) # 输出 5.0
.norm() 是 PyTorch 张量(torch.Tensor) 的方法。
矩阵常用 Frobenius 范数#
矩阵也有 “长度”—— 常用的是 Frobenius 范数
| 名称 | 记号 | 公式(对 $A\in\mathbb R^{m\times n}$) | 与向量的类比 |
|---|
| Frobenius 范数 | $\displaystyle|A|_F$ | $\displaystyle\sqrt{\sum_{i=1}^{m}\sum_{j=1}^{n}A_{ij}^{2}}$ | 就像向量 2 - 范数 $|v|=\sqrt {\sum v_i^2}$ |
1. 为什么也能写成 “矩阵点积”
在矩阵空间里常用的 内积 是
⟨A,B⟩:=tr(ATB),
其中 tr(⋅) 是迹运算(对角线元素之和)。
给 A 自己做这个内积,就得到
∥A∥F2=⟨A,A⟩=tr(ATA).
所以:
∥A∥F2=tr(ATA)
这正是矩阵版本的 ∥v∥2=vTv—— 只是把向量点积换成了 “迹点积”。
Frobenius 范数确实等于所有奇异值平方和的平方根,也就是:
∥A∥F=i∑σi2
这里:
Frobenius 范数确实等于所有奇异值平方和的平方根
展开解释:
Frobenius 范数定义为:
∥A∥F=i,j∑∣aij∣2
但奇异值分解(SVD)告诉我们:
A=UΣVT
其中 Σ 是对角矩阵,主对角线上就是奇异值 σ1,σ2,…。
因为 Frobenius 范数不变换(单位正交变换不改变范数),我们可以直接算:
∥A∥F2=i,j∑∣aij∣2=i∑σi2
所以最终:
∥A∥F=i∑σi2
小心误区
注意:
✅ 不是 单个奇异值平方根,也不是最大奇异值
✅ 是 所有奇异值平方后再相加取根号
谱范数看 “最能放大的一个方向”,Frobenius 则把所有能量都累加
矩阵的谱范数#
✅ 谱范数定义
矩阵 A 的谱范数(spectral norm)定义为:
∥A∥2=∥x∥2=1max∥Ax∥2
直白讲,就是 矩阵 A 把单位向量拉伸到多长的最大值。
奇异值本来就是表示矩阵的拉伸变换的。
它等于 A 的最大奇异值:
∥A∥2=σmax(A)
另一角度:谱范数 ≈ 把单位向量丢进矩阵后被拉伸的最大长度
✅ 它跟 Frobenius 范数的关系
换句话说:
-
Frobenius 像是矩阵 “体积” 总量感
-
谱范数像是 “最极端” 的单一方向放大率
✅ 例子:为什么它重要?
想象一个神经网络的线性层 $W$:
所以现代方法(比如 spectral normalization)
会直接在训练中把 W 的谱范数压制到一个范围内。
⚠ 直说缺点
谱范数很强,但:
概要对比
| 欧几里得范数 (2-norm, ‖v‖) | Frobenius 范数 (‖A‖F) |
|---|
| 对象 | 向量 v∈Rn | 矩阵 A∈Rm×n |
| 定义 | ∥v∥=i=1∑nvi2 | ∥A∥F=i=1∑mj=1∑nAij2 |
| 等价表达 | ∥v∥2=vTv | ∥A∥F2=tr(ATA)=∑kσk2 |
| 几何意义 | 向量在 n 维欧氏空间的长度 | 把矩阵元素按 “长向量” 看时的长度 |
| 单位 / 尺度 | 与坐标轴有同样度量 | 同上;对矩阵不依赖行列数的排列方式 |
| 常见用途 | 误差度量、正则化 L2、距离 | 权重衰减、矩阵近似误差、核方法 |
| 与谱范数关系 | ∥v∥=σmax(v) (仅一条奇异值) | ∥A∥F≥∥A∥2=σmax(A);若 rank = 1 则相等 |
1. 同一思路、不同维度
2. 何时用哪个?
| 场景 | 推荐范数 | 原因 |
|---|
| 预测误差、梯度下降 | 欧几里得 (向量残差) | 残差天然是列向量 |
| 网络权重正则 (Dense / Conv) | Frobenius | 不关心参数形状、仅关心整体幅度 |
| 比较矩阵逼近质量 (SVD, PCA) | Frobenius | 容易与奇异值平方和对应 |
| 稳定性 / Lipschitz 边界 | 谱范数 (∥A∥2) | 关心放大率而非总能量 |
3. 直观区别
一句话记忆:
欧几里得 范数:向量 “标尺”。
Frobenius 范数:把矩阵 “铺平” 后用同一把标尺量它的整体大小。
10、矩阵相乘的转置#
在矩阵代数里,两个(或多个)矩阵相乘后的转置有一个固定的 “翻转顺序” 规则:
(AB)T=BTAT.
也就是说 先转置每个矩阵,再把乘法顺序倒过来。
这一条性质对任何维度匹配的实(或复)矩阵都成立,而且可以递归推广:
(ABC)T=CTBTAT,(A1A2⋯Ak)T=AkT⋯A2TA1T.
xLog 编辑 Markdown 文档注意内容
参考视频:
点这里看 B 站视频